
Measuring levels of activity in a city after the adoption of COVID-19 mitigation measures
(march 2020 – ongoing)
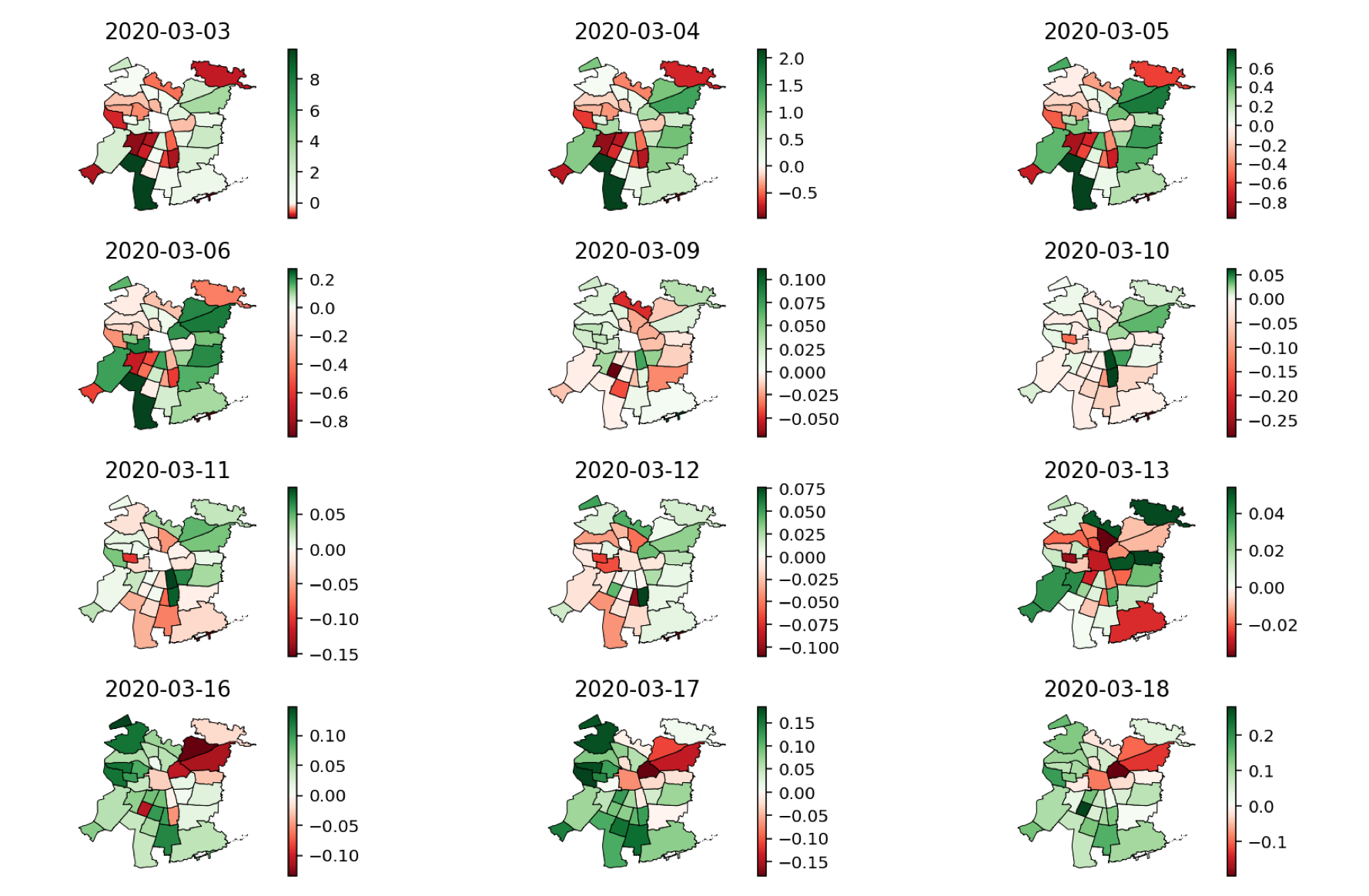
Chile, like many other countries, was closely monitoring the world as COVID19 was spreading, and learned from Europe, China and others in their handling of the virus. Some mitigation measures were already put in place by the Government on late February: on 02/24, some passengers on a cruise ship were quickly put under epidemiological observation; on 02/27, new measures were announced with respect to the strengthening of Chilean hospital infrastructure after a confirmed case in Brazil while, on the same day, the Chilean government announced that the COVID19 test was going to be free for everyone. On 03/02, every passenger arriving in Chile from abroad was to be surveyed and a COVID19 Protocol was enacted. The Ministry of Health confirmed the first person testing positive for COVID19 on March 3, 2020.
Main findings (so far):
1. After March 16th, when the first few measures were put in place (closing schools, reduced large gatherings), the city of Santiago defaulted to a weekend (Saturday) activity pattern.
2. After March 16, trips between antennas become shorter and more localized.
Measuring Levels of Activity in a Changing City: A Study Using Cellphone Data Streams, Technical Report, Instituto de Data Science, Faculty of Engineering, UDD
Authors: Leo Ferres, Rossano Schifanella, Nicola Perra, Salvatore Vilella, Loreto Bravo, Daniela Paolotti, Giancarlo Ruffo, Manuel Sacasa
The impact of socio-demographics over news consumption via smartphones
(11/2018 – 7/2019)
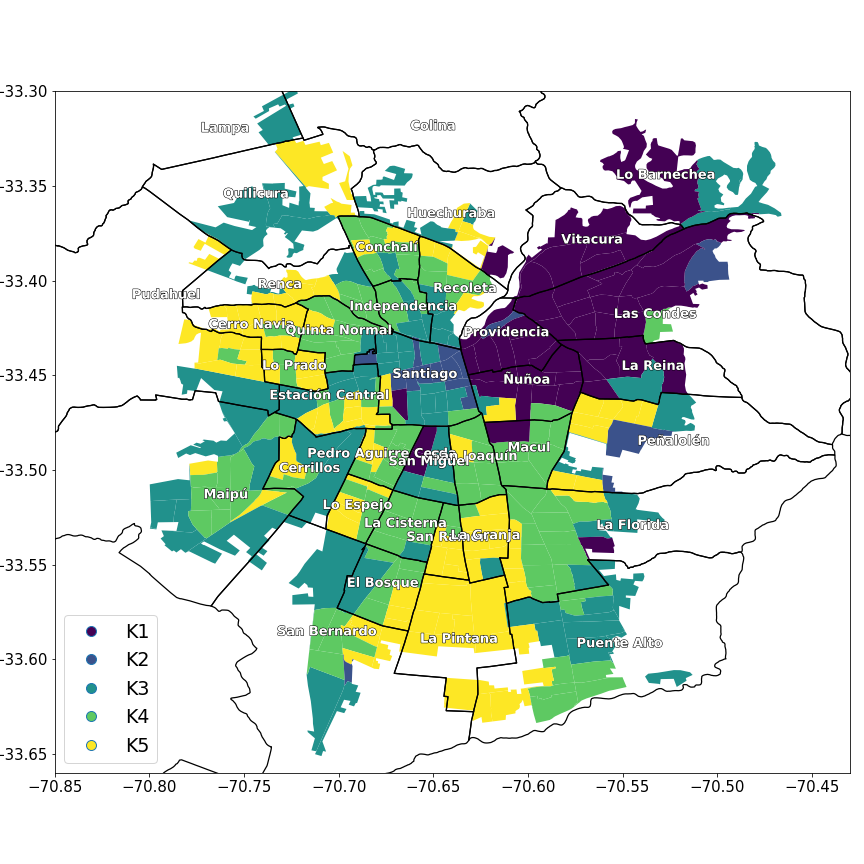
The always increasing mobile connectivity affects every aspect of our daily lives, including how and when we keep ourselves informed and consult news media. By studying mobile web data, provided by one of the major Chilean telecommunication companies, we investigate how different cohorts of the population of Santiago De Chile consume news media content through their smartphones. We address the issue of inequalities in the access to information, trying to understand to what extent socio-demographic factors impact the preferences and habits of the users.
Out on EPJ Data Science on April 2020.
Authors: S. Vilella, D. Paolotti, G. Ruffo.
Hubs and Authorities of the Scientific Migration Network
(04/2018 – ongoing)

The dimension of each node represents the hub value, while the color represents the authority value. Edge thickness stands for edge weight.
In this work we study international migrations of researchers, scientists, and academics from a complex-network prospective to identify the central countries involved in the migration phenomenon.
We define the Scientific Migration Network (SMN) as temporal directed weighted network where nodes are world countries, links account for the number of migrants moving from a country to another, and timestamps represent years (from 2000 to 2016). 2.8 millions ORCID public profiles are utilized as data source. We then characterize hubs and authorities of the SMN employing the well-know weighted hyperlink-induced topic search HITS algorithm to catch the interplay between exporting and importing researchers from a global prospective, and compare these results to other local and global methodologies. We also investigate the local characteristics of successors of hubs and predecessors of authorities to dive deeper into the motivations that establish hubs and authorities.
Finally, we showcase how to employ network visualization to evince temporal evolutions of ego-networks of selected hubs and authorities.
Authors: A. Urbinati, E. Galimberti, G. Ruffo.
On predicting the popularity of a programming language from Stackoverflow and GitHub activities.
(01/2019 – ongoing)
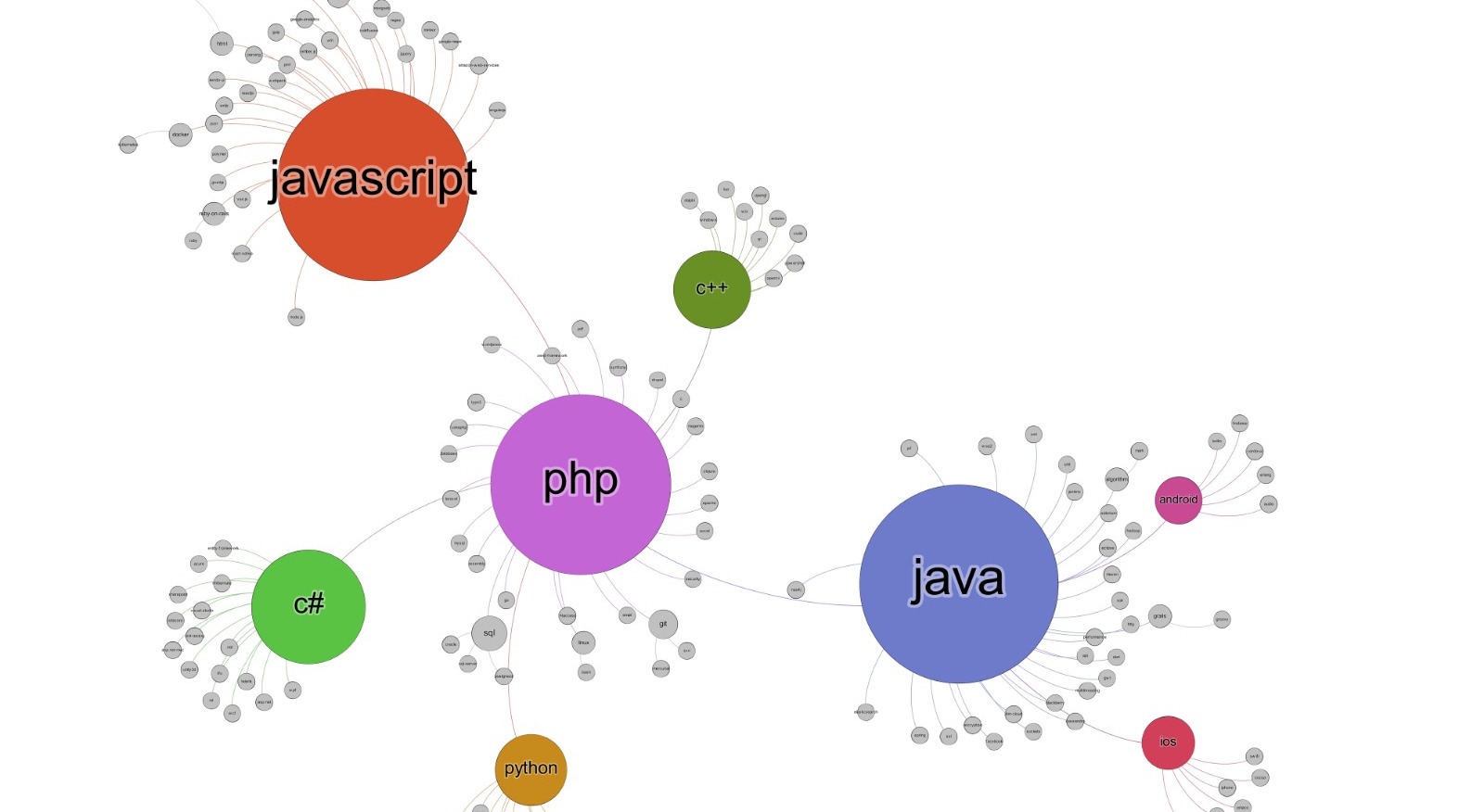
How a programming language spreads over time, getting much attention year by year, until it becomes a skill required in many job offers? There are undeniable conveniences for a company in the adoption of a language backed by a sustained community of developers, making it even more popular and supported, in a rich-get-richer process, but it’s hard to tell in a early stage which programming language will be the next big thing on the market. StackOverflow and GitHub are two very popular platforms supporting the activity of a programmer, the former by hosting a question and answer service about coding, the latter allowing programmers to backup and share their code. The amount of posts and repositories about a programming language can be easily used as proxy of the interest around it, and how it evolves year by year; also, important insights can be derived analyzing the network of the co-occurrences of coders in StackOverflow posts and GitHub repositories over different posts and repositories. Some of the repositories are marked as owned by companies, allowing for a influence on the market analysis. After collecting data about all the activities on both platforms from 2011 to 2019, we aim to find early indicators of a future success (or dismissing) of a programming language.
Authors: A. Semeraro, M. Faccin, G. Ruffo.
Which one is a fake news? Intrinsic features and externalities in news perception.
(03/2019 – 09/2020)
How do people tell a fabricated story from a real, documented news? Is the lexicon a hint? Do people read the whole article, or just its title? Do the source matters? Our opinion can be influenced not only by objective features intrinsic to the news, but also by externalities: as shown several times, social influence can shape our judgment, pushing us to adhere to other people’s opinion. We are working on a platform in which users are asked to tell wether a reported news is fake or not, while secretly changing features to show user by user in a random way: the full article rather than a short abstract, the source, other people’s opinion about a news, or a random opinion. The impact of these changes on the accuracy scores of users is to be evaluated. This study may shed light about what matters more when we build an opinion about what we read online.
Authors: A. Semeraro, T. Dimaggio, G. Ruffo.
Facing the problem of visual misinformation:
an actor based approach.
(10/2018 – 2019)

Multimedial fake news are a new, challenging problem. Unlike for textual hoaxes, there isn’t a search engine that allows to reconstruct the network of shares of a picture online.
An actor based approach can shrink the perimeter in which to search, highlighting the presence of malicious, coordinated actors.
This project has been selected among the three finalists at NATO StratCOM Challenge 2018. The spread of disinformation through fabricated or distorted multimedia contents is a challenging problem, with no simple solution, as most of current approaches fail to tell wether a picture conveys a false claim or not. An actor based approach can at least help to delimit a perimeter to search within for fabricated contents, and to reconstruct how a visual hoax get to be shared. In order to highlight hidden but stubborn fake news broadcasters on social media, we employed a simple methodology: first we crawled well known fake news providers in search of a network of mutual references involving other unknown fake news providers, then we collected all the tweets from users that posted contents originated in those websites. We also developed an image similarity search engine, in order to help analysts to reconstruct the network of sharing of a picture, linking togheter all those accounts that shared the same piece of content even when there is not a direct retweet.
Authors: A. Semeraro, M. Cerrato, F. Berger, S. Dibiase.
Behavioral patterns in financial transaction network.
(01/2017 – 03/2017)

In the context of a joint project between University of Turin and Banca Intesa Sanpaolo, one of the most important Italian banks, we analyzed a huge anonymized dataset containing all payments done by or to customers during 2016. We hence built a network where each node represents a bank account, and each edge a wire transfer, and here we show the results of an early network analysis. Nodes in the network show different behaviors according to their degree: while big hubs (mostly companies and institutions) are not connected among them, and share most of their connections with smaller nodes, small nodes (mostly private customers) send and receive payments both toward high and low degree nodes; they are indeed more clustered, probably in families and local groups. A bowtie anaylsis shows the role of small and medium businesses as the class of nodes holding the connectivity of the whole network.
Authors: A. Semeraro, M. Tambuscio, S. Ronchiadin, E. Galimberti, G. Ruffo.